Learning a Representative and Discriminative Part Model with Deep Convolutional Features for Scene Recognition
Abstract
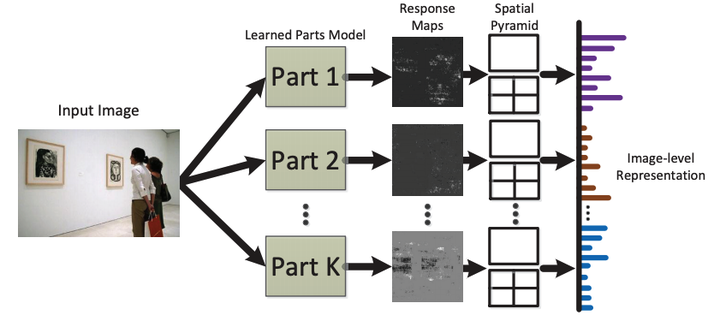
The discovery of key and distinctive parts is critical for scene parsing and understanding. However, it is a challenging problem due to the weakly supervised condition, i.e., no annotation for parts is available. To address above issues, we propose a unified framework for learning a representative and discriminative part model with deep convolutional features. Firstly, we employ selective search method to generate regions that are more likely to be centered around the distinctive parts, which is used as parts training set. Then, the feature of each part region is extracted by forward propagating it into the Convolutional Neural Network (CNN). The CNN network is pre-trained by the large auxiliary ImageNet dataset and then fine-tuned on the particular scene images. To learn the parts model, we build a mid-level part dictionary based on sparse coding with a discriminative regularization. The two terms, i.e., the sparse reconstruction error term and the label consistent term, indicate the representative and discriminative properties respectively. Finally, we apply the learned parts model to build image-level representation for the scene recognition task. Extensive experiments demonstrate that we achieve state-of-the-art performances on the standard scene benchmarks, i.e. Scene-15 and MIT Indoor-67.